n1cef1sh's Blog
题目
出处是bugkuCTF中的一个基础web题目,打开后显示
亲请在2s内计算老司机的车速是多少 354066340+849904764+1154118179+170808418-178952888+2104467671-889882972-1049253622*1730293155-901632172+624239913=?;
直接计算提交是不可的,因为很短时间里算式就会更新。刷新几次后,提示是post方式,参数名是value
Give me value post about 2081408248-1924494396+759137281+611407984-2020124941+1245099082+542064751+85787863916787594441169007952-2095025712=?
于是编写脚本实现提交答案。
py脚本
#!/usr/bin/python
# -*- coding: utf-8 -*-
import re,bs4
import requests
url = "http://123.206.87.240:8002/qiumingshan/"
#每次刷新算式会改变,session保持会话
ses = requests.Session()
res = ses.get(url)
content = res.content
txt = res.text
print(content)
#print(txt)
#获取div标签中算式的内容
#1.正则表达式
txt = re.search(r'(\d+[+-/*])+(\d+)',txt).group()
print(txt)
#2.bs4库
#将html源代码格式化,从而方便操作
# soup = bs4.BeautifulSoup(content,'lxml')
# print(soup)
# #从中取出算式
# txt = str(soup.find("div"))
# print(txt)
# txt = txt.split("=")[0].split(">")[1]
# print(txt)
#计算结果
result = eval(txt)
print(result)
# #将结果赋值并post上传
data = {
"value":result
}
s = ses.post(url,data=data)
print(s.text)
#Bugku{YOU_DID_IT_BY_SECOND}
几个姿势
1、编码问题:requests中的.text和.content
requests对象的get和post方法都会返回一个Response对象,这个对象里面存的是服务器返回的所有信息,包括响应头,响应状态码等。其中返回的网页部分会存在.content和.text两个对象中。 两者区别在于,content中间存的是字节码,而text中存的是Beautifulsoup根据猜测的编码方式将content内容编码成字符串。
直接输出content,会发现前面存在b’这样的标志,这是字节字符串的标志。而text没有前面的b。对于纯ascii码,这两个一模一样,对于其他的文字,需要正确编码才能正常显示。大部分情况建议使用.text,因为显示的是汉字,但有时会显示乱码,这时需要用.content.decode(‘utf-8’),中文常用utf-8和GBK,GB2312等。这样可以手工选择文字编码方式。
简而言之,.text是现成的字符串,.content还要编码,但是.text不是所有时候显示都正常,有时需要用.content进行手动编码。
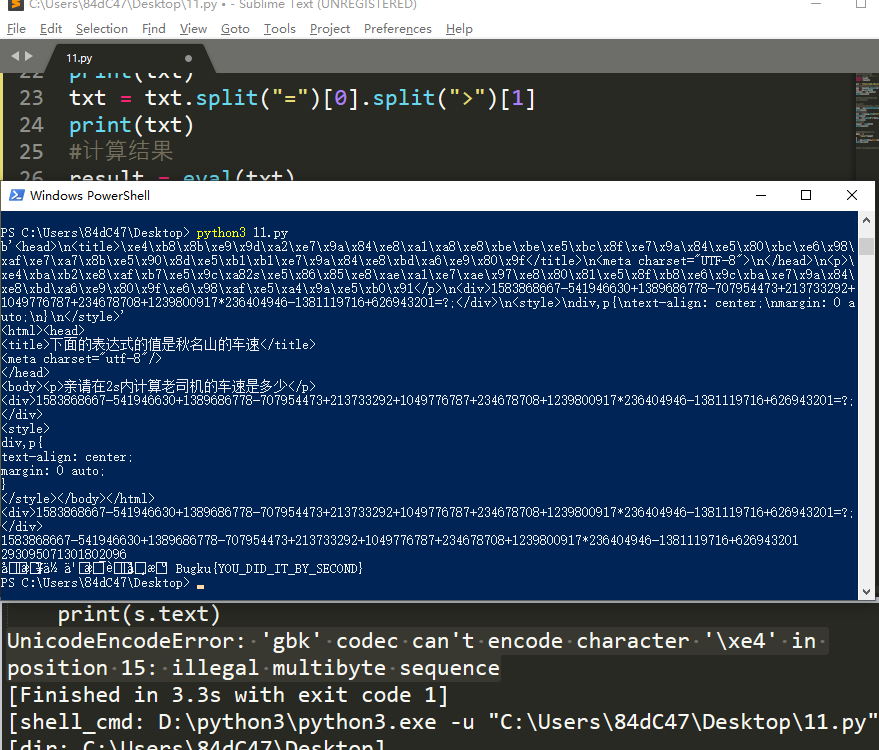
在最后post答案后获取返回值时,print(s.text)有时会报错(有时候也可以直接正常输出)
#报错:UnicodeEncodeError: 'gbk' codec can't encode character '\xe4' in position 15: illegal multibyte sequence
测试发现在cmd命令窗口和sublime text中执行均会出现这种情况,但是Windows的powershell不会。
涉及到编码的问题一般只是有点麻烦(个人感觉),这里就是print()函数自身有限制,不能完全打印所有的unicode字符。于是尝试在print打印前再次声明编码
s = ses.post(url,data=data)
s.encoding = 'utf-8'
print(s.text)
这样就可以正常完成输出。
2、正则表达式
txt = re.search(r'(\d+[+-/*])+(\d+)',txt).group()
这句正则表达式也比较简单,按照数字和加减乘除匹配即可。
group()用来提出分组截获的字符串,()用来分组 ,例如
import re
a = "111sss777"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #111sss777,返回整体,不写0也一样
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #111,返回第一个括号分组
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #sss,返回第二个括号分组
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #777,返回第三个括号分组
若没有匹配成功,re.search()返回None
3、bs4库
BeautifulSoup库是一个灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页信息的提取。直接用pip安装即可。
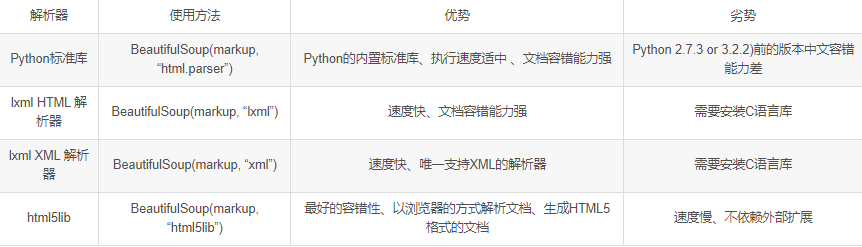
使用合适的解析器,将html源代码格式化,从而方便进一步对内容进行操作。
4、eval()
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
小结
积累姿势,提高水平。